Vectors represent unstructured data and are essentially lists of decimal numbers. When vectors are used in semantic search, we refer to vector embeddings.
The term “embedding” helps reflect the transformation of data to a lower-dimensional space while preserving the features of the original data
the vector embeds the structures and relationships of the original data (which may be the semantic meaning of a paragraph or the attributes like colors, angles, lines, and shapes in a picture, and so on).
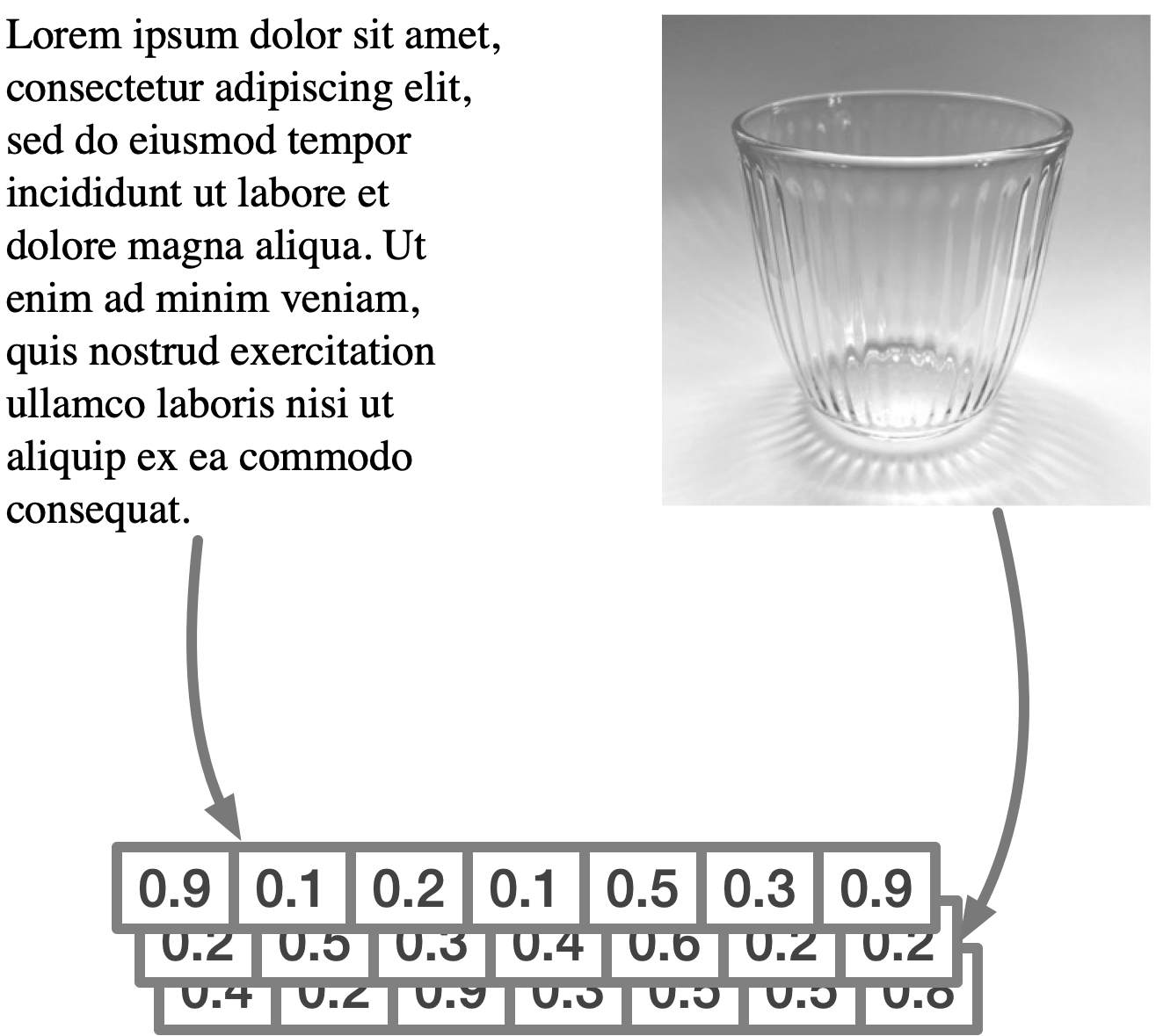
What are vector embeddings?
A vector is a mathematical structure with a size and a direction. For example, we can think of the vector as a point in space, with the “direction” being an arrow from (0,0,0) to that point in the vector space.
As developers, it might be easier to think of a vector as an array containing numerical values. For example:
vector = [0,-2,...4]
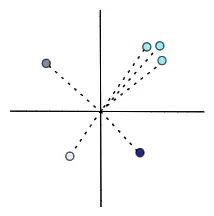
When we look at a bunch of vectors in one space, we can say that some are closer to one another, while others are far apart. Some vectors can seem to cluster together, while others could be sparsely distributed in the space.
How to create vector embeddings?
The availability of pre-trained machine learning models has helped spread and standardize the approach. In practice, many machine learning projects use pre-trained embedding models as a starting point, and benchmarking and fine-tuning them for the specific task helps introduce semantic search into a service
When a machine learning model generates vectors, they embed the distinctive features of data into floating point numbers of fixed size in a compact and dense representation and translate the human-perceived semantic similarity to the vector space.
The semantic similarity of two objects translates to the “numerical similarity” of two vectors, which is calculated as the distance between vectors, a simple mathematical operation.
Examples of embeddings:
pip install imgbeddings
pip install sentence_transformers
Text Embeddings:
# generate_text_embeddings.py
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("sentence-transformers/all-MiniLM-L6-v2")
text = (
"This is a technical document, it describes the SID sound chip of the Commodore 64"
)
embedding = model.encode(text)
print(embedding[:10])
Image embedding:
# generate_image_embeddings.py
import requests
from PIL import Image
from imgbeddings import imgbeddings
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
ibed = imgbeddings()
embedding = ibed.to_embedding(image)
print(embedding[0][0])
Embedding models
If we want to compare 2 sentences only using vectors and the proximity between them we just compare the words accuracy and not compare the semantic meanings of the sentences.
So, to solve that problem, we can use an embedding model like mxbai-embed-large, This types of model are trained with amount of labeled data to a neural network.
The embedding model is basically this neural network with the last layer removed. Instead of getting a specific labeled value for an input, we get a vector embedding.