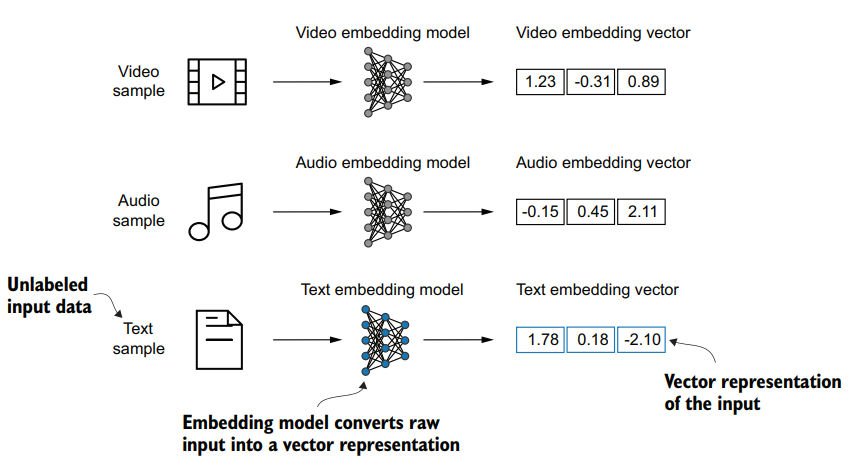
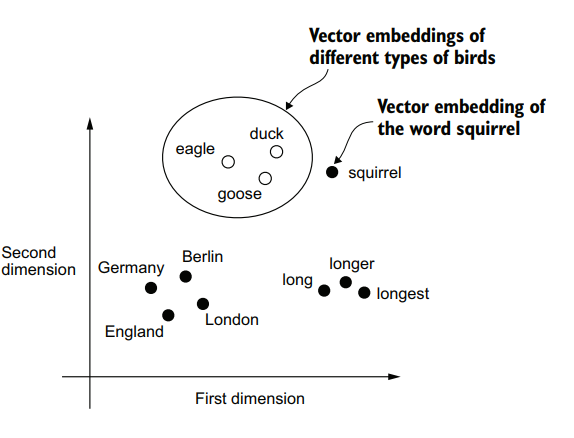
Understanding word embeddings
embedding When transform some kind of data into a vector.
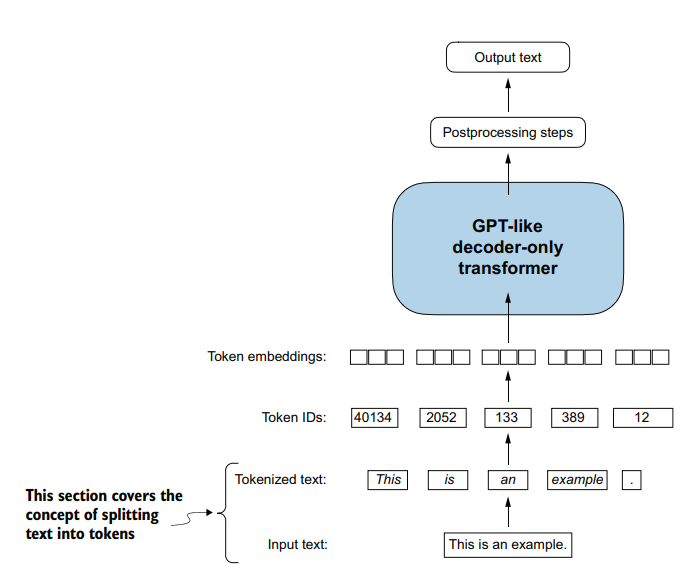
Tokenizing text
So, for tokenize text we need separate each word and characters into a individual words. Then we can represent each simple word with a one unique id, for do this we create a vocabulary within repeated words or characters.
Separate a sentence:
import re
text = "Hello, world. Is this-- a test?"
result = re.split(r'([,.:;?_!"()\']|--|\s)', text)
result = [item.strip() for item in result if item.strip()]
print(result)['Hello', ',', 'world', '.', 'Is', 'this', '--', 'a', 'test', '?']Create a vocabulary:
# sort alphabetically and remove duplicates
all_words = sorted(set(result))
# create a vocabulary
vocab = {token:integer for integer, token in enumerate(all_words)}('!', 0) ('"', 1) ("'", 2) ('(', 3) (')', 4) (',', 5) ('--', 6) ('.', 7) (':', 8) (';', 9) ('?', 10) ('A', 11) ('Ah', 12) ('Among', 13) ('And', 14) ('Are', 15) ('Arrt', 16) ('As', 17) ('At', 18) ('Be', 19) ('Begin', 20) ('Burlington', 21) ('But', 22) ('By', 23) ('Carlo', 24)
...
('Has', 47) ('He', 48) ('Her', 49) ('Hermia', 50)We now have a vocabulary in which each word has an integer as its id. We can use this for create a inverse vocabulary for decode our integer sentences.
class SimpleTokenizerV1:
def __init__(self, vocab):
self.str_to_int = vocab
self.int_to_str = {i:s for s,i in vocab.items()}
def encode(self, text):
preprocessed = re.split(r'([,.?_!"()\']|--|\s)', text)
preprocessed = [item.strip() for item in preprocessed if item.strip()]
ids = [self.str_to_int[s] for s in preprocessed]
return ids
def decode(self, ids):
text = " ".join([self.int_to_str[i] for i in ids])
text = re.sub(r'\s+([,.?!"()\'])', r'\1', text)
return texttokenizer = SimpleTokenizerV1(vocab)
text = """"It's the last he painted, you know,"
Mrs. Gisburn said with pardonable pride."""
ids = tokenizer.encode(text)
print(ids)[1, 56, 2, 850, 988, 602, 533, 746, 5, 1126, 596, 5, 1, 67, 7, 38, 851, 1108, 754, 793, 7]print(tokenizer.decode(ids))" It' s the last he painted, you know," Mrs. Gisburn said with pardonable pride.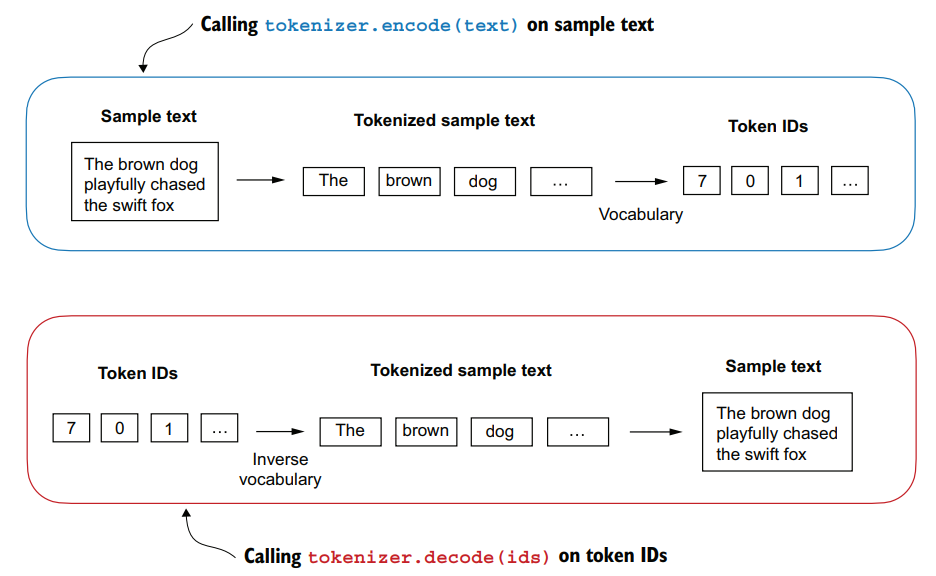
Handling unexpected tokens
Suppose that the vocab not contain the word "Hello", if we try tokenize a sentence with this word we get an Error.
text = "Hello, do you like tea?"
print(tokenizer.encode(text))KeyError: 'Hello'For handle these situations we can add specifics tokens. For example we can add tokens like "<|unk|>" for indicate that the work is unknown and "<|endoftext|>" for indicate that this is the end of text.
all_tokens = sorted(set(preprocessed))
all_tokens.extend(["<|endoftext|>", "<|unk|>"])
vocab = {token: integer for integer, token in enumerate(all_tokens)}
print(len(vocab.items()))
for i, item in enumerate(list(vocab.items())[-5:]):
print(item)1132
('younger', 1127)
('your', 1128)
('yourself', 1129)
('<|endoftext|>', 1130)
('<|unk|>', 1131)Then we need modify our SimlpeTokenizer for changes the unknown words for the token "<|unk|>"
class SimpleTokenizerV2:
def __init__(self, vocab):
self.str_to_int = vocab
self.int_to_str = {i: s for s, i in vocab.items()}
def encode(self, text):
preprocessed = re.split(r'([,.:;?_!"()\']|--|\s)', text)
preprocessed = [item.strip() for item in preprocessed if item.strip()]
preprocessed = [
item if item in self.str_to_int else "<|unk|>" for item in preprocessed
]
ids = [self.str_to_int[s] for s in preprocessed]
return ids
def decode(self, ids):
text = " ".join([self.int_to_str[i] for i in ids])
text = re.sub(r'\s+([,.:;?!"()\'])', r"\1", text)
return texttext1 = "Hello, do you like tea?"
text2 = "In the sunlit terraces of the palace."
text = " <|endoftext|> ".join((text1, text2))
print(text)Hello, do you like tea? <|endoftext|> In the sunlit terraces of the palace.If tokenize the text we see the numbers 1131 and 1130 that belong to tokens "<|unk|>" and "<|endoftext|>"
tokenizer = SimpleTokenizerV2(vocab)
print(tokenizer.encode(text))[1131, 5, 355, 1126, 628, 975, 10, 1130, 55, 988, 956, 984, 722, 988, 1131, 7]And if we decode the ids we get this:
tokenizer = SimpleTokenizerV2(vocab)
print(tokenizer.encode(text))<|unk|>, do you like tea? <|endoftext|> In the sunlit terraces of the <|unk|>.Data sampling with a sliding window
In this step we need create the input-targets pairs for train LLMs
We use tiktoken as tokenizer for encode and decode our text.
enc_text = tokenizer.encode(raw_text)
print(len(enc_text))What is?
Basically LLMs are pretrained by predicting the next word in a text. So, we get the inputs and then we move the target 1 positions for get the target.

enc_sample = enc_text[50:]
context_size = 4
x=enc_sample[:context_size]
y=enc_sample[1:context_size+1]
print(f"x: {x}")
print(f"y: {y}")x: [290, 4920, 2241, 287]
y: [4920, 2241, 287, 257]for i in range(1, context_size):
context = enc_sample[:i]
desired = enc_sample[i]
print(context, "---->", desired)[290] ----> 4920
[290, 4920] ----> 2241
[290, 4920, 2241] ----> 287if decode the tokens:
for i in range(1, context_size):
context = enc_sample[:i]
desired = enc_sample[i]
print(tokenizer.decode(context), "---->", tokenizer.decode([desired]))and ----> established
and established ----> himself
and established himself ----> inSo, we create our Dataset with based on this concept. We receive a text and then split en inputs and target chunks.
Look this, take a input chunk using the max_length and move 1 position for get the target.
import torch
from torch.utils.data import Dataset, DataLoader
class GPTDatasetV1(Dataset):
def __init__(self, txt, tokenizer, max_length, stride):
self.input_ids = []
self.target_ids = []
token_ids = tokenizer.encode(txt)
for i in range(0, len(token_ids) - max_length, stride):
input_chunk = token_ids[i : i + max_length]
target_chunk = token_ids[i + 1 : i + max_length + 1]
self.input_ids.append(torch.tensor(input_chunk))
self.target_ids.append(torch.tensor(target_chunk))
def __len__(self):
return len(self.input_ids)
def __getitem__(self, idx):
return self.input_ids[idx], self.target_ids[idx]The we create our data loader
def create_dataloader_v1(
txt,
batch_size=4,
max_length=256,
stride=128,
shuffle=True,
drop_last=True,
num_workers=0,
):
tokenizer = tiktoken.get_encoding("gpt2")
dataset = GPTDatasetV1(txt, tokenizer, max_length, stride)
dataloader = DataLoader(
dataset,
batch_size=batch_size,
shuffle=shuffle,
drop_last=drop_last,
num_workers=num_workers,
)
return dataloader
dataloader = create_dataloader_v1(
raw_text, batch_size=1, max_length=4, stride=1, shuffle=False
)
data_iter = iter(dataloader)
first_batch = next(data_iter)
print(first_batch)[tensor([[ 40, 367, 2885, 1464]]), tensor([[ 367, 2885, 1464, 1807]])]Creating token embeddings
Now, we need to convert the token IDs into embedding vectors. Create the embedding layer:
vocab_size = 50257
output_dim = 256
torch.manual_seed(123)
token_embedding_layer = torch.nn.Embedding(vocab_size, output_dim)
print(token_embedding_layer)Embedding(50257, 256)
Parameter containing:
tensor([[ 1.4424, 2.6252, -0.0923, ..., 1.9454, -1.1768, 0.8824],
[-0.4691, 1.2547, -1.3212, ..., -1.5919, -0.0203, -0.6094],
[ 0.2324, -0.9103, -0.4608, ..., 1.5701, -0.2833, -0.4178],
...,
[ 0.4721, 0.4064, -2.4622, ..., -0.2801, -1.0035, -0.2706],
[-0.0434, 0.6163, -0.3900, ..., -0.6484, -0.2449, 1.6638],
[ 0.6332, -1.2952, 0.4919, ..., 0.8049, 0.6275, -0.0446]], requires_grad=True)
Next thing is create a data loader and pass this dataloader to the embedding layer
max_length = 4
dataloader = create_dataloader_v1(
raw_text, batch_size=8, max_length=max_length, stride=max_length, shuffle=False
)
data_iter = iter(dataloader)
inputs, targets = next(data_iter)
print("Token IDs:\n", inputs)
print("Targets:\n", targets)
print("\nInputs shape:\n", inputs.shape)Token IDs:
tensor([[ 40, 367, 2885, 1464],
[ 1807, 3619, 402, 271],
[10899, 2138, 257, 7026],
[15632, 438, 2016, 257],
[ 922, 5891, 1576, 438],
[ 568, 340, 373, 645],
[ 1049, 5975, 284, 502],
[ 284, 3285, 326, 11]])
Targets:
tensor([[ 367, 2885, 1464, 1807],
[ 3619, 402, 271, 10899],
[ 2138, 257, 7026, 15632],
[ 438, 2016, 257, 922],
[ 5891, 1576, 438, 568],
[ 340, 373, 645, 1049],
[ 5975, 284, 502, 284],
[ 3285, 326, 11, 287]])
Inputs shape: torch.Size([8, 4])token_embeddings = token_embedding_layer(inputs)
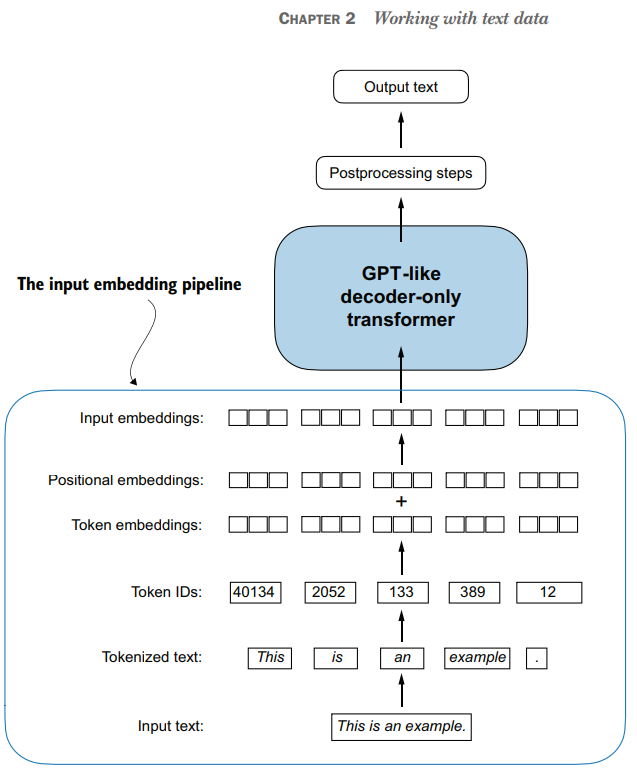
print(token_embeddings.shape)torch.Size([8, 4, 256])The last thing is create a Absolute positinal embeding this is importar because help to the model to understand the position of each token.
context_length = max_length
pos_embedding_layer = torch.nn.Embedding(context_length, output_dim)
pos_embeddings = pos_embedding_layer(torch.arange(context_length))
print(pos_embeddings.shape)tensor([[-0.8194, 0.5543, -0.8290, ..., 0.1325, 0.2115, 0.3610],
[ 0.4193, -0.9461, -0.3407, ..., 0.7930, 1.7009, 0.5663],
[-0.2362, -1.7187, -1.0489, ..., 1.1218, 0.2796, 0.9912],
[-0.9549, 0.4699, 0.2580, ..., -1.3689, 1.6505, 1.3488]],
grad_fn=<EmbeddingBackward0>) torch.Size([4, 256])input_embeddings = token_embeddings + pos_embeddings
print(input_embeddings.shape)torch.Size([8, 4, 256])